
How GPT Reads Your Words (And Why It Can’t Count Letters)
Part of the MiniGPT series: Learn by Building


TL;DR
GPT doesn’t see letters; it sees tokens (subword chunks). “strawberry” becomes [”straw”, “berry”], which is why counting R’s is hard. This single design choice explains mysterious behaviours, API costs, and why your prompts sometimes get truncated. Understanding tokens is now as fundamental as understanding databases for anyone building with LLMs.
You type:
“How many R’s are in strawberry?”
Early versions of ChatGPT would often reply:
“There are two R’s in strawberry.”
Wrong. There are three.
Modern models like GPT-5 usually get this right. But they’re getting it right despite how they read text, not because of it.
When you type “strawberry,” the model does not see s-t-r-a-w-b-e-r-r-y. It sees two tokens, something like:
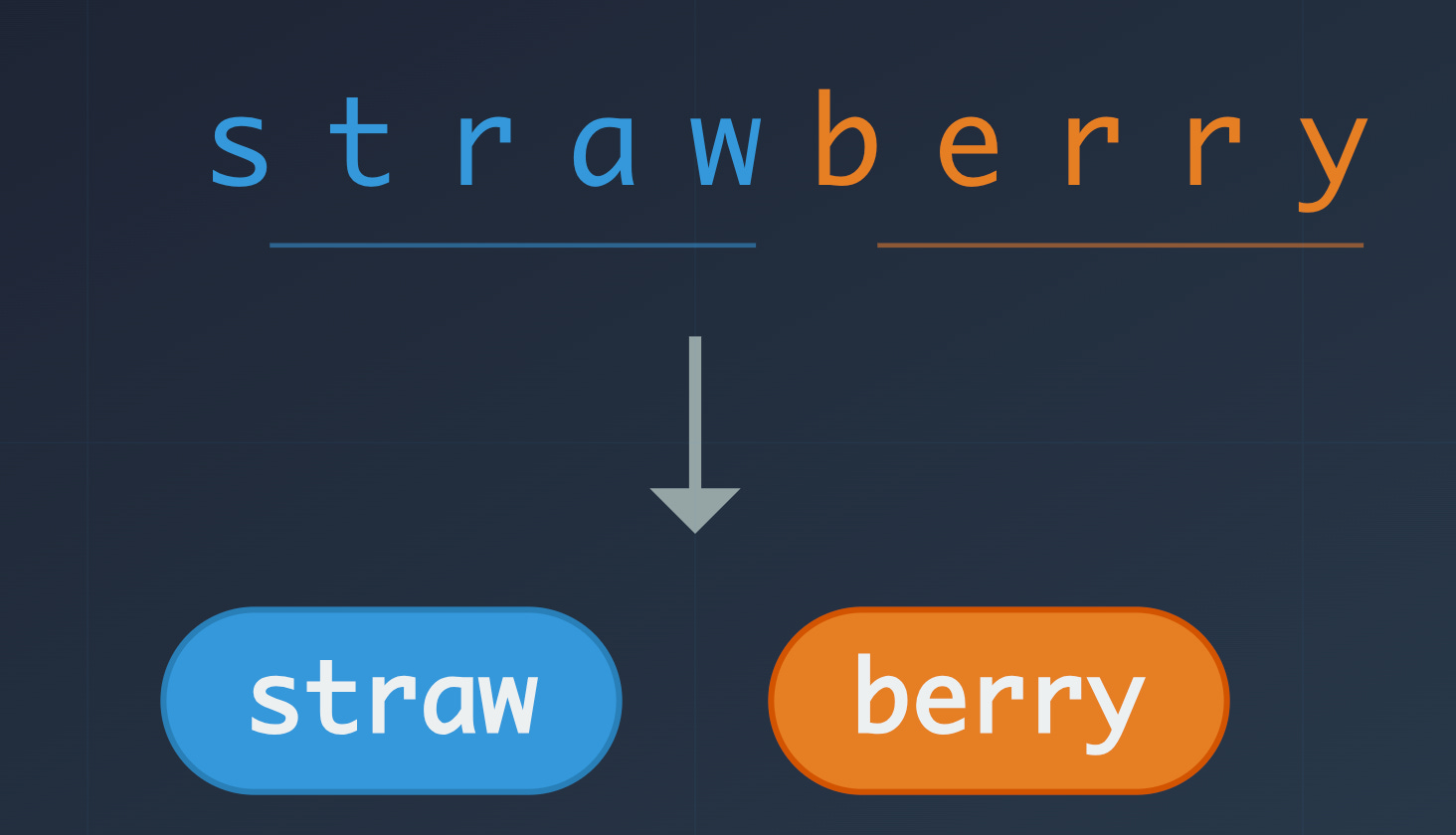
To count the R’s, the model has to work around its own representation. It needs to reason about spelling even though the architecture never promised it could see characters at all.
That single design choice, how text is chopped up into tokens, explains a lot of behaviour that feels mysterious:
Why letter counting, reversing strings, and simple ciphers are surprisingly hard
Why API costs spike with certain kinds of content
Why does your prompt sometimes get silently truncated, and instructions vanish
If you’re building production systems on top of LLMs, tokenization is not an academic detail. It’s the first place bugs and costs start to show up.
💡 All the code you see here (and a lot more) is in the MiniGPT repo with Colab notebooks you can run yourself.
Why Understanding This Matters Right Now
Three years ago, knowing how to call an API was enough. Today, understanding how LLMs work is becoming as fundamental as understanding databases or networking.
Here’s why this specific topic tokenization is worth your time.
1. You’re Already Building With LLMs
If you’re:
Integrating ChatGPT in your product
Using GitHub Copilot
Indexing documents with embeddings
...you’re already making architectural decisions around tokens, context windows, and costs.
One line of code that ignores token limits can:
Truncate your prompt in production
Drop the most important part of a document
Double your bill without changing a single word of UI copy
2. The Abstraction Is Leaking
The nice mental model of “I send text, I get text back” holds until:
The model hallucinates after a small prompt change
A long prompt quietly stops following your last instruction
A user pastes some code, and your token counts explode
At that point, “vibes-based” prompt engineering stops working. The people who understand tokens, attention, and probabilities are the ones who can actually debug and improve the system.
3. The Market Has Moved
“LLM experience” on a job description rarely means “can call the OpenAI API.”
It usually means:
Can reason about context limits
Can estimate and control token costs
Can design systems that combine LLMs with traditional components
You don’t need to become a research scientist. But you do need to know what’s really happening when you send a text to a model.
4. It’s Much Less Scary Than It Looks
You already know the ingredients:
Strings
Arrays
Integers
Some probability
We’re just going to put those pieces together in a way that explains what GPT is doing behind the scenes.
By the end of this series, when the next major model ships, you won’t just read the marketing page. You’ll look for:
What tokenizer does it use
How large is the context window really in practice
Where the failure modes are going to show up
The Core Insight: Tokens, Not Letters
Here’s what you think happens when you send a text to GPT:
“strawberry”
↓
[’s’, ‘t’, ‘r’, ‘a’, ‘w’, ‘b’, ‘e’, ‘r’, ‘r’, ‘y’]
Here’s what actually happens:
“strawberry”
↓ [Tokenizer]
[”straw”, “berry”]
↓ [Token IDs]
[496, 15717]
GPT never sees letters. It only sees integers. Every model call is “take this sequence of integers and predict the next integer.”
That one detail explains a lot:
Letter counting is not “free” like it is for humans
String reversal is hard without an explicit character-level tool
Small whitespace or punctuation changes can alter the meaning the model perceives
What Is Tokenization?
Tokenization is the step that turns text into something a neural network can work with.
Conceptually:
Your sentence
↓
Tokenizer
↓
[Tokens]
↓
[Token IDs]
↓
Embeddings and transformer layers
Example:
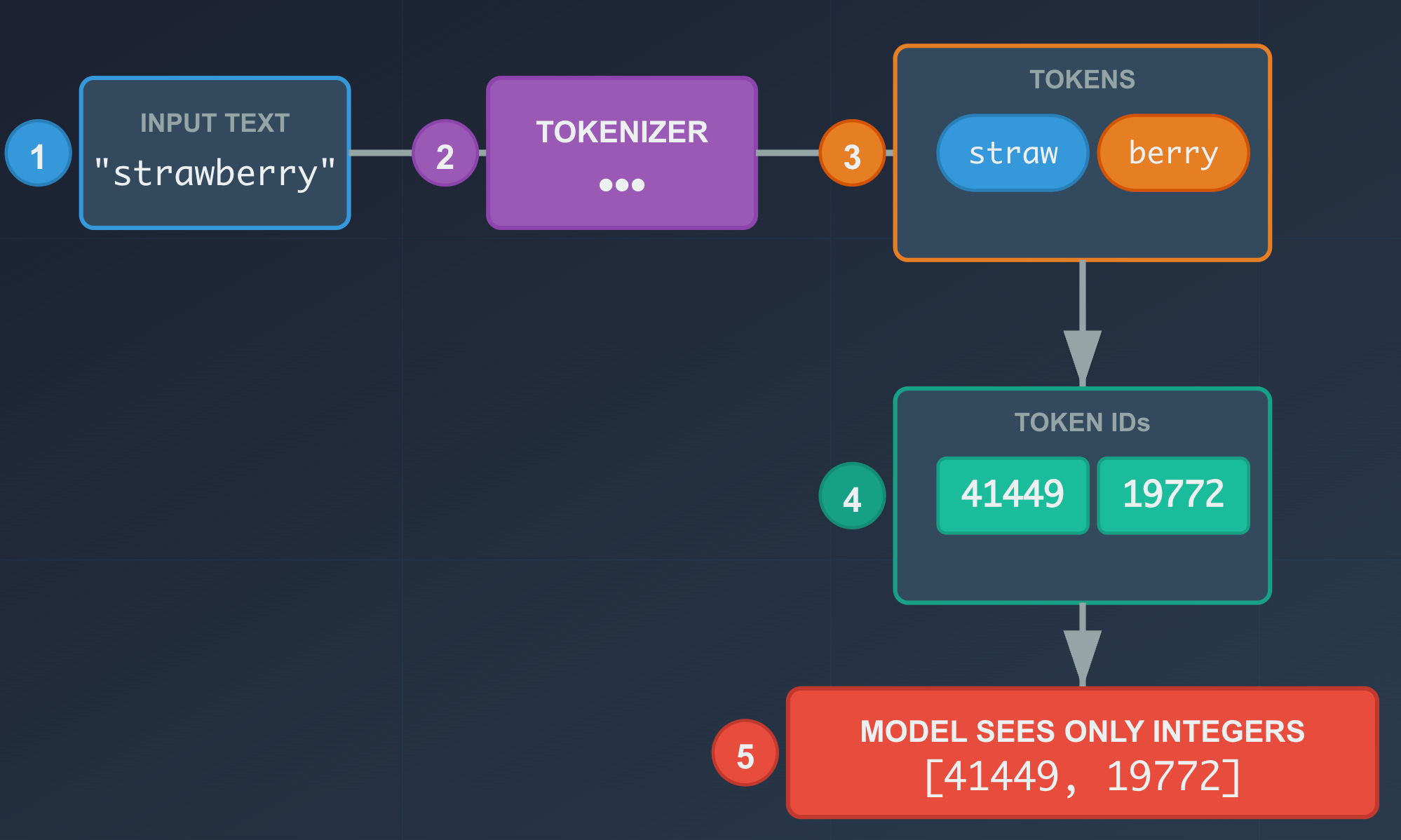
Everything that looks “smart” later is built on top of this representation.
Why Not Just Use Characters?
The obvious question is: why not just give the model one token per character and be done with it?
Character-Level
“Hello world”
→ [”H”, “e”, “l”, “l”, “o”, “ “, “w”, “o”, “r”, “l”, “d”]
→ 11 tokens
Pros:
Simple
Fixed vocabulary (roughly 256-byte values)
Never out-of-vocabulary
Cons:
5-10× more tokens for the same text
Smaller effective context window
The model has to learn everything from scratch at the character layer
Word-Level
“Hello world”
→ [”Hello”, “world”]
→ 2 tokens
Pros:
Intuitive
Each token has a clear meaning
Cons:
Vocabulary explodes into the millions
Fails on new words, typos, usernames, weird formatting
Subword-Level (What GPT Uses)
Subword tokenization aims for a balance:
Common words become single tokens
Rare words are split into smaller pieces
Everything can still be represented
“ChatGPT” → [”Chat”, “GPT”]
“unbelievableness” → [”un”, “believ”, “able”, “ness”]
“strawberry” → [”straw”, “berry”]This choice is what makes models like GPT feasible in the first place.
How Byte Pair Encoding (BPE) Works
Modern GPT-style models use a variant of Byte Pair Encoding.
You don’t need to memorize the algorithm, but understanding the idea pays off.
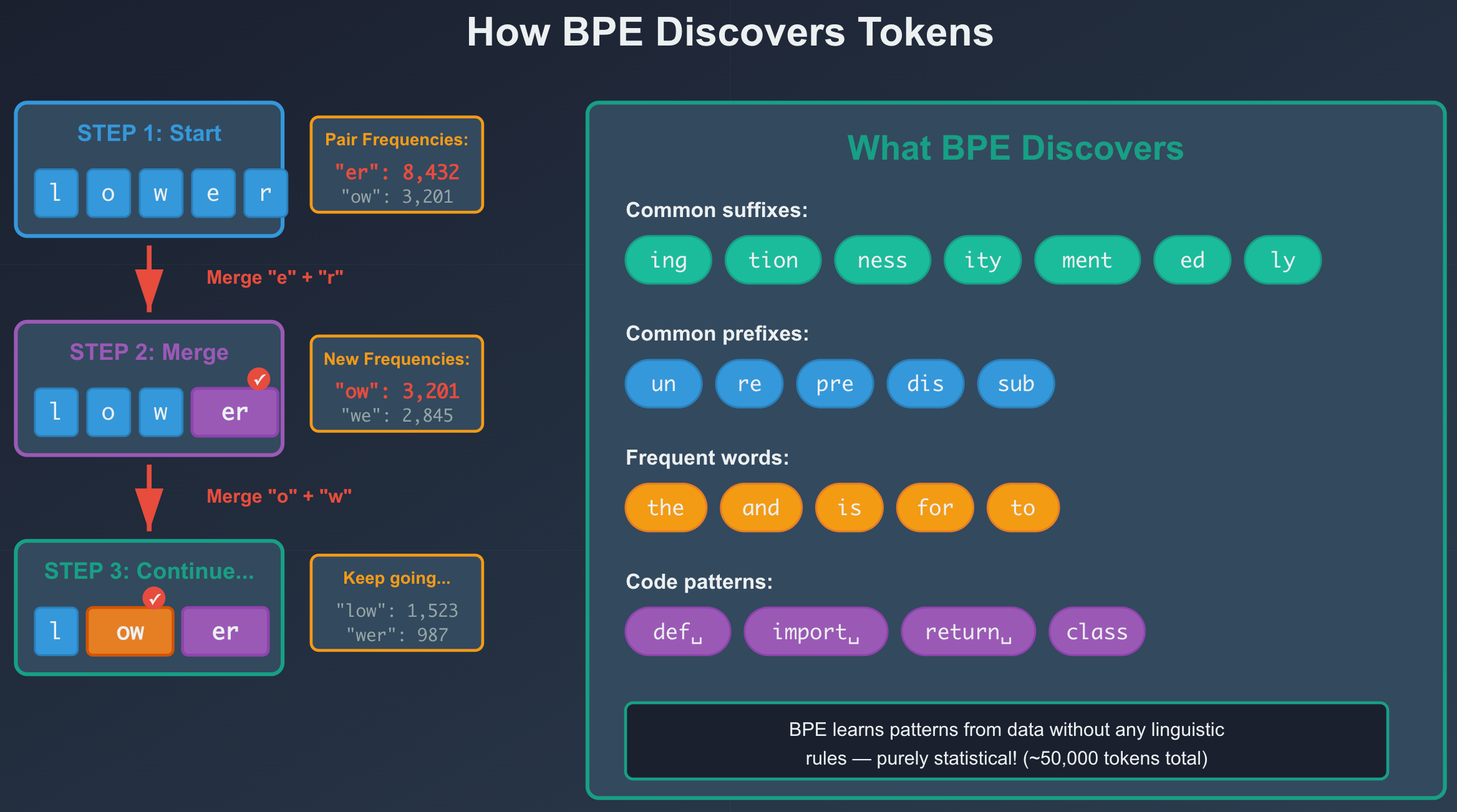
The Training Idea, In Plain Language
Start with individual bytes as your basic tokens
Look at a huge corpus of text
Find the most frequent pair of tokens that occur together
Merge that pair into a new token
Repeat until you have the desired vocabulary size
Widespread patterns become tokens:
“the”
“ing”
“ion”
“ ChatGPT”
Rare patterns stay as combinations of existing tokens or bytes.
Why This Is Powerful
BPE discovers structure without any linguistic rules. It will naturally learn:
Suffixes like “ing”, “ness”, “tion”
Prefixes like “un”, “re”
Common code patterns like
def,import,return
From the model’s point of view, tokens are just IDs. But the tokenizer has arranged things so that frequent, meaningful chunks have their own IDs.
A Tiny Longest-Match Tokenizer
To make this concrete, here’s a tiny “toy” tokenizer that behaves a bit like a BPE tokenizer at runtime.
We won’t train anything here. We just assume a tiny vocab that already contains some subwords:
def simple_tokenizer(text, vocab):
“”“Greedy longest-match tokenizer.”“”
tokens = []
i = 0
while i < len(text):
matched = False
# Try longest possible substring first
for length in range(len(text) - i, 0, -1):
piece = text[i:i + length]
if piece in vocab:
tokens.append(vocab[piece])
i += length
matched = True
break
if not matched:
# Unknown token
tokens.append(vocab.get(”<UNK>”, 0))
i += 1
return tokens
# Our tiny vocabulary
vocab = {
“Hello”: 101,
“ world”: 102,
“!”: 103,
“straw”: 201,
“berry”: 202,
“<UNK>”: 0,
}
print(simple_tokenizer(”Hello world!”, vocab))
# Output: [101, 102, 103]
print(simple_tokenizer(”strawberry”, vocab))
# Output: [201, 202]
The important part is the strategy: always take the longest matching piece. Real GPT tokenizers follow the same greedy idea, just with a much larger and more complex vocabulary.
The actual BPE training and a fuller tokenizer implementation live in the repo. You don’t need all of that in your head to benefit from understanding what it’s doing.
Real Tokenization With tiktoken
Now, let’s look at how OpenAI’s tokenizer, tiktoken, sees the same text.
import tiktoken
encoder = tiktoken.get_encoding(”gpt2”) # close enough for examples
# Simple sentence
text = “Hello world!”
tokens = encoder.encode(text)
print(tokens)
# Output: [15496, 995, 0]
print([encoder.decode([t]) for t in tokens])
# Output: [’Hello’, ‘ world’, ‘!’]
# The strawberry example
text = “strawberry”
tokens = encoder.encode(text)
print(tokens)
# Output: [41449, 19772]
print([encoder.decode([t]) for t in tokens])
# Output: [’straw’, ‘berry’]
Key observations:
“Hello world!” is 3 tokens, not 12
“strawberry” is 2 tokens, even though it has 10 characters
“straw” and “berry” are meaningful chunks that the tokenizer discovered
Spaces Matter More Than You Think
One of the surprising details in GPT tokenizers is how they handle spaces.
text1 = “hello”
text2 = “ hello”
tokens1 = encoder.encode(text1)
tokens2 = encoder.encode(text2)
print(tokens1, [encoder.decode([t]) for t in tokens1])
print(tokens2, [encoder.decode([t]) for t in tokens2])
Typical output looks like:
[31373] [’hello’]
[23748] [’ hello’]
So:
“hello”is one token“ hello”(with a leading space) is also one tokenBut they are different tokens
The tokenizer encodes the space into the token itself. That’s why models usually generate “ world” as one token instead of “ “ followed by “world”.
This Has Implications
Adding or removing spaces changes the token sequence
Slightly different prompts can have different costs and behaviour, even if they look the same at a glance
When you’re debugging strange behaviour, whitespace can be part of the story
Gotchas That Actually Bite You
Once you know how tokens work, you start to see a few failure modes over and over.
1. Token Counts Are Not Intuitive
This kind of thing is common:
examples = [
“cat”,
“cats”,
“ChatGPT”,
“GPT-4”,
]
for text in examples:
tokens = encoder.encode(text)
print(f”{text!r}: {len(tokens)} token(s)”)
You might get:
‘cat’: 1 token
‘cats’: 1 token
‘ChatGPT’: 2 tokens # [’Chat’, ‘GPT’]
‘GPT-4’: 3 tokens # [’G’, ‘PT’, ‘-4’]
So a short string like “GPT-4” can be more expensive than it looks, especially when you’re dealing with a lot of IDs, symbols, or emojis.
Why “GPT-4” becomes 3 tokens: The tokenizer sees ‘G’ as rare enough to be separate, ‘PT’ as a common chunk (from words like “ception”), and ‘-4’ as a number with punctuation. This is why brand names and technical identifiers often tokenize unexpectedly.
2. Token Limits Are Hard Limits
Models have a fixed context size, expressed in tokens, not characters or words.
For example, if a model has an 8,192-token limit:
You cannot send 8,193 tokens
Anything beyond the limit is effectively invisible to the model
In many APIs, the excess text is silently truncated from the end
That’s how you get bugs like:
“The model ignored the last instruction”
“The summary stops mid-sentence”
“Some sections of the document were not considered”
The text is not being ignored on purpose. It simply never made it into the context window.
3. Word-Count Heuristics Lie To You
Rough mental rules like:
“1 token ≈ 4 characters”
“1 token ≈ 0.75 words”
...are fine for back-of-the-envelope estimates, but they’re not accurate enough for anything serious.
The only reliable approach if you care about correctness or cost is:
tokens = encoder.encode(text)
actual_count = len(tokens)
This is especially true for:
Code
Mixed-language content
Emoji-heavy text
Anything with a lot of punctuation or math
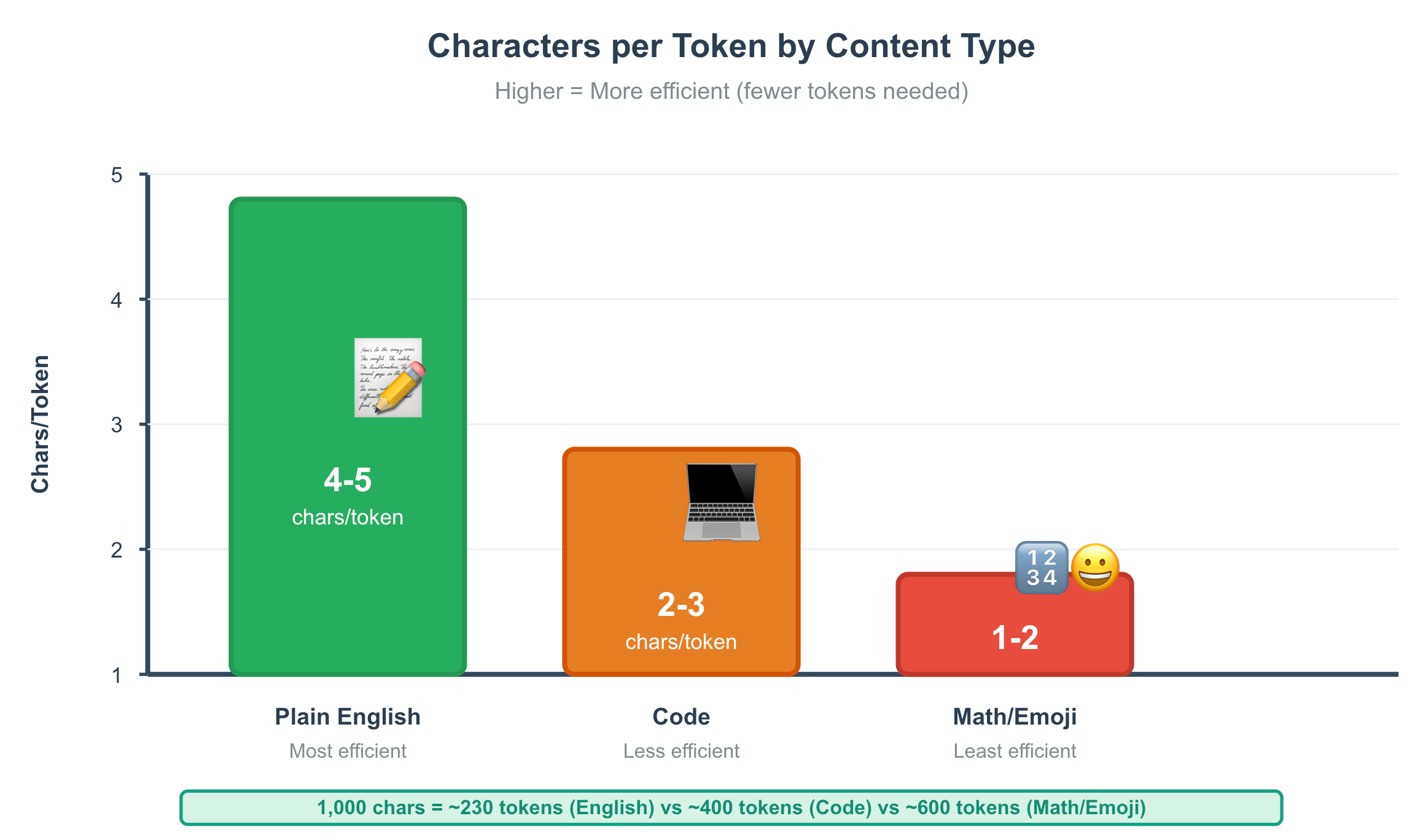
Token Efficiency Across Text Types
Different kinds of text “compress” differently into tokens.
In practice, you’ll see patterns like:
Content Type Typical Chars/Token Plain English prose 4-5, Code 2-3, Math notation, emoji, rare symbols 1-2
The Practical Point
A 1,000-character essay might be ~230 tokens
A 1,000-character code snippet might be ~400 tokens
If your product sends a lot of code to an LLM, your token bill will not look like your character count.
A Small Helper To Inspect Tokenization
Here’s a short helper that you can drop into your own code to understand how a string is being tokenized.
import tiktoken
encoder = tiktoken.get_encoding(”gpt2”)
def analyze(text: str) -> None:
“”“Analyze how text is tokenized.”“”
tokens = encoder.encode(text)
pieces = [encoder.decode([t]) for t in tokens]
print(f”Text: {text!r}”)
print(f”Characters: {len(text)}”)
print(f”Tokens: {len(tokens)}”)
if tokens:
print(f”Chars per token: {len(text) / len(tokens):.2f}”)
print(”\nToken breakdown:”)
for i, (tid, piece) in enumerate(zip(tokens, pieces)):
# Make whitespace visible
visible = (
piece
.replace(” “, “␣”)
.replace(”\n”, “↵”)
)
print(f” {i:2d}. id={tid:5d} piece={visible!r}”)
# Try it out
analyze(”Hello world!”)
print()
analyze(”strawberry”)
Output example:
Text: ‘Hello world!’
Characters: 12
Tokens: 3
Chars per token: 4.00
Token breakdown:
0. id=15496 piece=’Hello’
1. id= 995 piece=’␣world’
2. id= 0 piece=’!’
Use it to try:
Your name
Your product name
A typical user prompt
A code snippet from your app
You’ll very quickly build intuition for what’s cheap, what’s expensive, and where surprising splits happen.
All of this is built out more fully in the notebook, including nicer formatting and comparison helpers.
The Bigger Picture
Tokenization is only the first step in the pipeline, but it sets the ground rules for everything that follows.
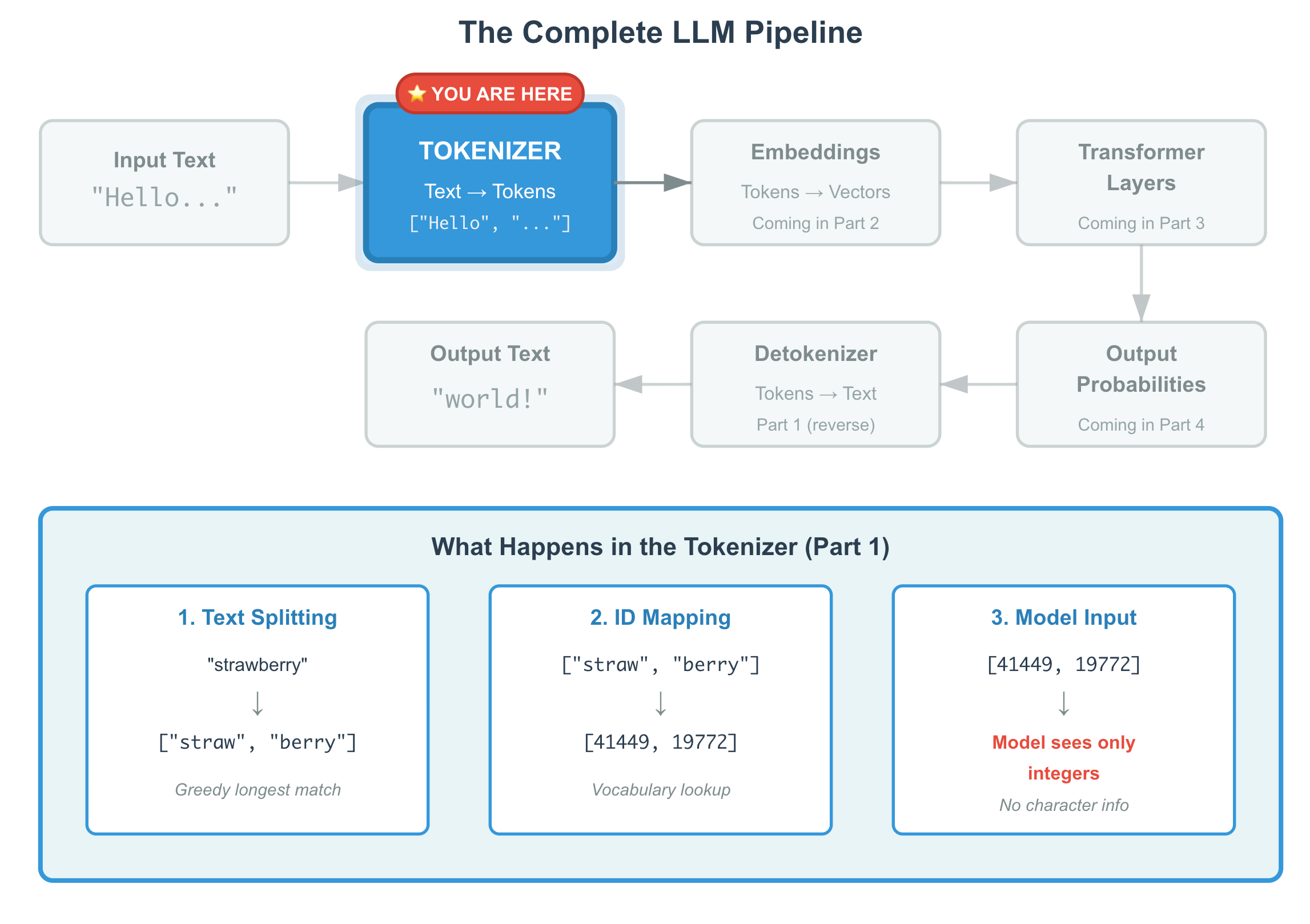
It:
Defines what the model can see at once
Shapes how meaning is represented
Controls how much you pay
Introduces quiet failure modes if you ignore it
Once text is tokenized, the model throws away the original character boundaries. From that point on, it’s all vectors and matrices.
Understanding this step makes the next step much easier to follow.
In Part 2 we’ll take those token IDs and turn them into embeddings: high-dimensional vectors that capture meaning in a way that allows the model to reason. That’s where analogies like king - man + woman ≈ queen come from. We’ll build the embedding layer ourselves so you can see that this is not magic either.
What To Do With This As A Builder
If you’re building with LLMs today, you can start applying this immediately:
Log token counts for your prompts and responses
Add checks that truncate or summarize text before you hit model limits
Run your own product prompts through a tokenization helper and look for surprises
Refine prompt templates to reduce tokens without losing meaning
You don’t need to obsess over every token, but you do need to know when tokens start to dominate your costs and your failure modes.
Repo: github.com/naresh-sharma/mini-gpt
Colab: Tokenization notebook
Discussion: GitHub Discussions
This is Part 1 of the MiniGPT series.